
سرویس تبدیل متن به گفتار و همچنین تبدیل گفتار به متن گوگل مبتنی بر هوش مصنوعی، درحال توسعه است. کاربرانی که از سرویس ابری گوگل یا گوگل کلاود استفاده میکنند، بهزودی ویژگیهای جدیدی دریافت خواهند کرد.
شرکت مانتینویو اعلام کرد که بهروزرسانیهای قابلتوجهی برای سرویس ابری تبدیل متن به گفتار در پیش است که میتواند متن نوشتاری را با الگوهای مختلف، تبدیل به گفتار کند؛ بهطوری که قابلیت پخششدن در دستگاههای مختلف را داشته باشد. ویژگیهای جدید دیگری نیز به سرویس تبدیل متن به گفتار گوگل مبتنی بر هوش مصنوعی اضافه شده است که یکی از آنها، امکان تشخیص چند کانال نام دارد.
اولین ویژگی توسعهیافته در سرویس تبدیل متن به گفتار ابری گوگل، امکان سنتز پیشرفتهی گفتار را فراهم میکند. با این ویژگی جدید، با استفاده از برنامهی WaveNet، نهتنها امکان تبدیل متن به گفتار وجود دارد، بلکه کاربران میتوانند به خروجی نهایی در چندین زبان مختلف دسترسی داشته باشند. ویژگی جدید توسط دیپمایند، یکی از شرکتهای تابعهیآلفابت و با فناوری مبتنی بر یادگیری ماشینی توسعه یافته است. همچنین، بهروزرسانی جدید به سیستم اجازه میدهد تا الگوی متن را تشخیص دهد و براساس الگوی نوشتاری متن، کلمات و جملات را بهگونهای به گفتار تبدیل کند که آهنگ خوانش جملات و استرس روی کلمات بهدرستی ادا شوند و متن بازخوانیشده، هرچه بیشتر به الگوی خوانش انسانی نزدیکتر باشد. با کمک سختافزار TPU ابری گوگل، متن تبدیلشده به فایل صوتی بهصورت صحیحتر و نزدیکتر به ادای کلمات توسط انسان، بیان میشود. برنامهی WaveNet میتواند نمونهی اولیهی یک ثانیهای از متن تبدیلشده به گفتار را در زمانی کمتر از ۵۰ میلیثانیه تولید کند.

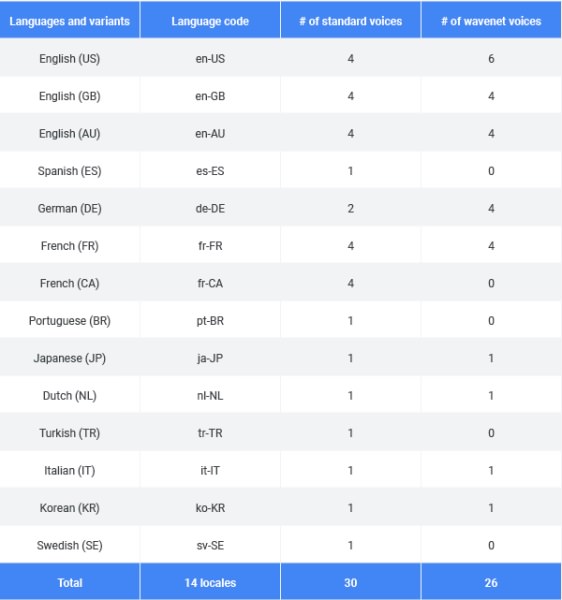
در حالحاضر، سرویس تبدیل متن به گفتار ابری گوگل میتواند ۱۷ فرمت صدای مختلف ویونت را به کاربر پیشنهاد بدهد و از ۱۴ زبان مختلف پشتیبانی میکند. در کل، این سرویس میتواند ۵۶ صدای مختلف تولید کند، که ۳۰ صدای استاندارد و ۲۶ صدای ویونت به کاربر پیشنهاد داده میشود. فهرست کامل این صداها در وبسایت گوگل وجود دارد.
پشتیبانی گستردهتر و وسیعتر از صدای WaveNet، تنها ویژگی جدیدی نیست که به این سرویس اضافه شده است. علاوهبر افزایش تعداد صداهای ویونت، نسخهی اصلی پروفایلهای صوتی که پیشتر نسخهی بتا آن در دسترس بود، منتشر میشود.
پروفایلهای صوتی به کاربر اجازه میدهد تا او، گفتار تولیدشده توسط APIهای سرویس تبدیل متن به گفتار ابری گوگل را برای پخش در سختافزارهای مختلف بهینهسازی کند. کاربر میتواند نمایهای برای دستگاهها و گجتهای پوشیدنی مختلف خود با اسپیکرهای کوچکتر ایجاد کند. ایجاد این نمایه، خصوصا برای دستگاههایی که از فرکانسهای خاصی پشتیبانی نمیکنند، بسیار مناسب خواهد بود و اگر صدای تولیدشده خارج از محدودهی فرکانسی شنوایی باشد، آن را به محدودهی شنوایی تغییر وضعیت میدهد و صدایی با کیفیت بهتر را در اختیار کاربر قرار میدهد. تیم تحقیقاتی Google Cloud که روی توسعهی سرویس تبدیل متن به گفتار فعالیت میکنند، اعلام کرده است:
ویژگیهای فیزیکی هر دستگاه و همچنین محیطی که دستگاه در آن قرار دارد، روی فرکانسها و برخی جزئیات سیگنال تاثیرگذار هستند؛ مثلا میتوانند روی مواردی ازجمله باس، treble و حجم صدا تاثیرگذار باشند. نمونهی اولیهی صوتی که توسط سیستم تولید میشود، معمولا ممکن است در مقایسه با صدایی که در اسپیکر لپتاپ تولید میشود، بدتر و ضعیفتر باشد؛ ولی کیفیت صدای بهتری نسبت به صدایی که از خطوط تلفن منتقل میشود، خواهد داشت.
در بهروزرسانی جدید، هشت دستگاه جدید پشتیبانی میشوند:
- گجتهای پوشیدنی مثلا دستگاههای با سیستمعامل Wear OS
- گوشیهای هوشمند
- هدفون
- اسپیکرهای کوچک با پشتیبانی از بلوتوث (مثل گوگل هوم مینی)
- اسپیکرهای با ابعاد متوسط با قابلیت پشتیبانی از بلوتوث (مثل گوگل هوم)
- سیستم های سرگرمی خانگی ( مثل گوگل هوم مکس)
- اسپیکر خودرو
- سیستمهای پاسخ صوتی تعاملی (IVR)

بهروزرسانیهای مربوط به سرویس تبدیل گفتار به متن گوگل کلاود
گوگل در کنفرانس توسعهدهندگان Google Cloud Next در ماه جولای (تیرماه)، به برخی از ویژگیهای جدید سرویس تبدیل گفتار به متن خود اشاره کرد و اکنون سه ویژگی را بهصورت برجستهتری معرفی میکند؛ که عبارتند از : تشخیص چند کاناله (Multichannel Recognition) ، تشخیص خودکار زبان (Language Auto-detect) و بالابردن درصد اطمینان ادای درست واژه (Word-level Confidence).
تشخیص چند کاناله یا Multichannel Recognition، امکان تخصیص کانالهای صوتی چندگانه را فراهم میکند. امکان تخصیص اتوماتیک کانالهای مختلف برای هر کلمه وجود دارد. گوگل متوجه شده است که با کمک این ویژگی و امکان تخصیص چندین کانال، امکان تهیهی بهترین کیفیت خروجی برای کاربر فراهم میشود. برای نمونههای صوتی که بهصورت جداگانه ضبط نمیشوند، سرویس ابری تبدیل گفتار به متن با کمک فناوریهای مبتنی بر یادگیری ماشین، برای هر کلمه تگ یا برچسبی را تعیین میکند، که برچسب هر کلمه مربوط به یکی از اسپیکرهای سیستم خواهد بود. با گذشت زمان، دقت برچسبها بهبود پیدا میکند.
ویژگی بعدی تشخیص خودکار زبان (Language Auto-detect) است، که میتواند زبان متن را بهصورت اتوماتیک تشخیص دهد. سیستم میتواند کدهای مربوط به چهار زبان را بهصورت همزمان در فهرست Query خود ارسال کند. API بهصورت خودکار، زبان فایل صوتی را تشخیص میدهد و آن را به متن نوشتاری تبدیل میکند. روش کار تقریبا مشابه روشی است که گوگل اسیستنت زبان را تشخیص میدهد و پاسخ متناسب را ارائه میکند. البته، کاربران میتوانند بهصورت دستی نیز زبان مورد نظر خود را تنظیم کنند.
آخرین ویژگی، بالابردن درصد اطمینان ادای درست واژه (Word-level Confidence) نام دارد که به توسعهدهندگان کمک میکند تا کنترل دقیقی بر موتور تشخیص گفتار گوگل داشته باشند. کاربران میتوانند در برنامههای مختلف، کلماتی خاص را با تاکید به برنامه ادا کنند. مثلا گاهی لازم میشود کلماتی مهم و خاص در جمله، مجددا تکرار شوند تا کاربر مطمئن شود که سیستم، واژه را درست متوجه شده است. این ویژگی، کاربران را تشویق میکند تا کلمات را درستتر و دقیقتر ادا کنند و اگر لازم شد کلمات را با لحنی شمردهتر و آرامتر ادا کنند. گوگل در مورد این ویژگی توضیح میدهد:
فرض کنید در اپلیکیشن این جمله را گفتهاید: «قرار ملاقاتی با جان برای ساعت ۲ بعدازظهر فردا تنظیم کن». اگر کاربر تمایل داشته باشد، میتواند کلماتی مثل«جان» یا «ساعت ۲ بعدازظهر» را مجددا تکرار کند تا مطمئن شود برنامه اشتباه متوجه منظورش نشده است. میتواند حتی این دو کلمه را با لحنی آرامتر و شمردهتر ادا کند تا اطمینان حاصل کند که برنامه اشتباه متوجه نشده است.
قطعا ویژگیهای جدید میتوانند منجر به افزایش رضایت کاربران از سیستم تبدیل متن به گفتار و سیستم تبدیل گفتار به متن Google شوند.
.: Weblog Themes By Pichak :.
